A Brief History of Modern Data Stack
07-10-2024
The origin - a legend
The origin of the modern data stack is a topic of intense debate, shrouded in uncertainty and mystery. Some attribute its incubation to Snowflake, Redshift, or Airflow, while others propose different theories. Rather than being the result of a single event, the term "modern data stack" emerged from a series of innovations and industry shifts, adding to the intrigue of its history. The foundation of the modern data stack was laid by the creation of Apache Yarn, initially a subproject of Hadoop, later promoted as an Apache top-level project. This might come as a surprise, but by the time Apache Yarn was incubated, S3 as a data store had already gained popularity, leading to the separation of storage and computing. This context is crucial for understanding the evolution of the modern data stack. Despite significant advancements, the Big Data project failure rate remains alarmingly high, with over 85% of projects failing to meet their objectives. The industry is grappling with the key reasons behind Hadoop's diminishing promise—a struggle that resonates with many.
Systems like Apache Hive and Presto started to bridge this gap, but the overall infrastructure remained expensive, challenging companies to justify the cost. Eventually, Hadoop was declared dead. However, Presto demonstrated the possibility of querying massive datasets with scalable storage and computing, paving the way for systems like Redshift, Snowflake, and Databricks to address these pain points and simplify data processing. The rise of cloud data warehouses has given birth to a suite of tools now collectively known as the Modern Data Stack. The Golden Days
Source: https://medium.com/vertexventures/thinking-data-the-modern-data-stack-d7d59e81e8c6 Everything has become a SaaS offering in the modern data stack world, particularly attractive to companies struggling with Big Data infrastructure. The modern data stack filled the gap for companies eager to leverage their data without the prohibitive costs of maintaining Hadoop-based infrastructure. It brought large-scale data processing power with the flexibility to scale as needed. A wide array of tools emerged, allowing companies to build, buy, and manage data without the burden of maintaining infrastructure. This shift enabled companies to focus on extracting value from data—a dream sold by the modern data stack.
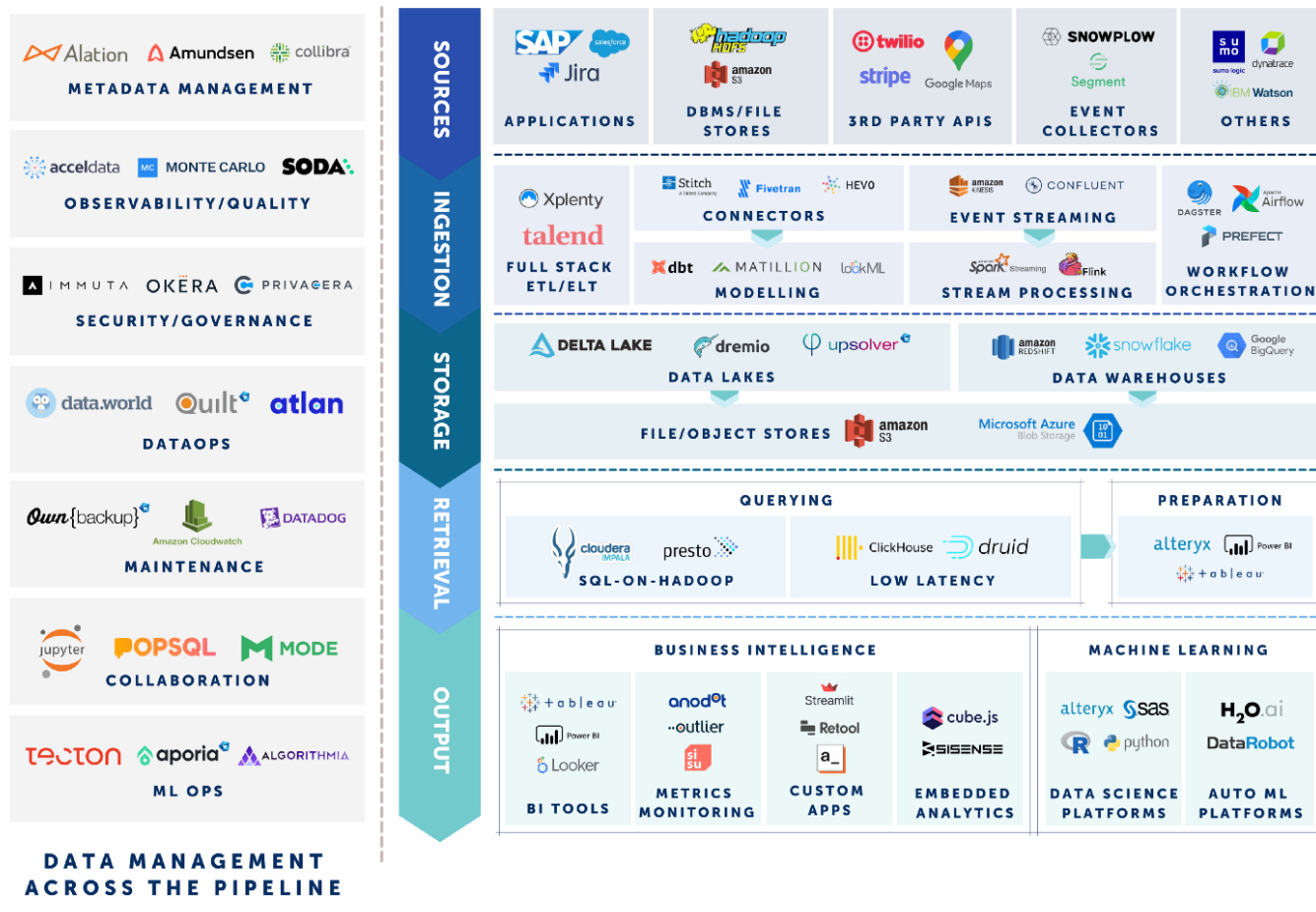
The explosion of data tools, each targeting specific functions of data engineering, combined with substantial venture funding, significantly accelerated the growth of the modern data stack. The modern data stack ecosystem began to resemble a giant mural of logos, each representing a different tool or platform. The DownfallThe modern data stack had an amazing impact on data engineering, bringing a developer-first user experience for the first time. However, its very success contributed to its eventual downfall. As companies increasingly adopted these tools, they encountered three major problems: high costs, difficulty integrating, and confusion among themselves.
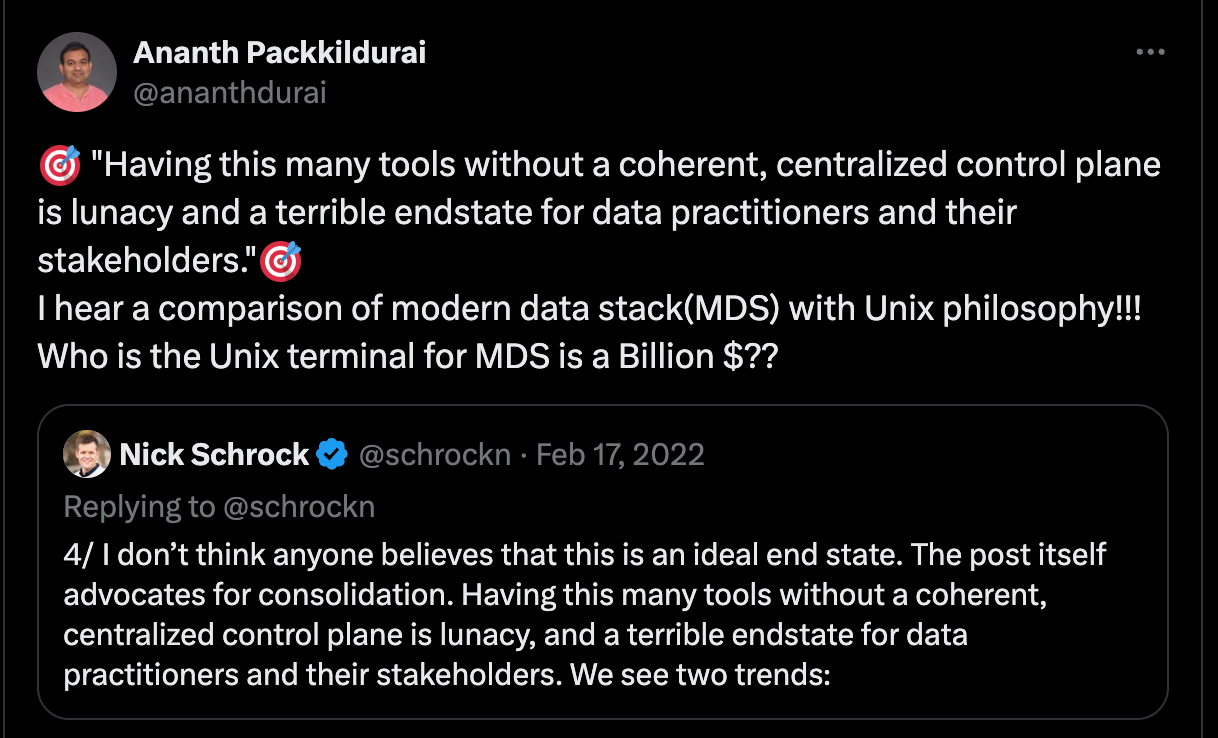
The Hidden CostInitially, the simplicity and scalability of the modern data stack were appealing. Single-click scaling and ease of use made it a company's go-to solution. However, these advantages led to uncontrollable operational costs. As interest rates rose, companies started to prioritize cost optimization. This was a poor fit for the modern data stack, as the ecosystem encouraged using multiple tools, resulting in high data team budgets. The "Modern Data Stack High-Speed Tax" became a term used to describe the cost burden associated with the modern data stack, as highlighted in Instacart’s widely debated S1 filing. Integration IssuesThe following two Twitter threads summarize the integration issue with Modern Data Stack. In a growth economy, everyone wants to be the control plane for everyone else, resulting in high integration costs and poor overall experience.
The Failed Unix Analogy
Eventually, we declared the modern data stack is dead 🙂here, here & here. Post-Modern Data Stack (Next Gen Data Stack)The sequence of events shows that nothing is accidental; one event leads to another. Now, the bigger question is, what comes next? The recent AI data infrastructure value chain doesn’t differ greatly from the Modern Data Stack of 2022. The Next-Gen Data Stack (#Next-Gen Data Stack aka NDS) will learn from the mistakes of the Modern Data Stack but improve its efficiency.
Key properties of the Next-Gen Data Stack are Embrace Open InteroperabilityWe started to see the pattern with open table formats. Major data infrastructure companies have started to embrace open table formats, and there are projects like Apache XTable and UniForm that have ensured these table formats are interoperable. Databricks and Snowflake announce the open-source versions of their catalogs on top of open table formats. Keep Developer Productivity FirstThe Next-Gen Data Stack continues the modern data stack's philosophy of simplifying tool usage to enhance developer productivity. The goal is to create tools that are easy to use and accessible to a broad audience. If the tools become too complex, they risk failing to penetrate the mass market. Cost EfficientThe Next-Gen Data Stack will emphasize cost optimization to address rising operational expenses strongly. Companies will increasingly seek cost-efficient solutions to set budgets and control expenses effectively. For instance, using S3 as a standard storage solution for event logging in infrastructures like Kafka illustrates this trend. Integrating the data stack, reducing infrastructure complexity, open interoperability, and enhanced visibility into spending versus value are key drivers of cost efficiency. By prioritizing these elements, the Next-Gen Data Stack aims to deliver a more economical and sustainable approach to data management. Standardize: Don’t Make Me ThinkFinally, one of the reasons that resulted in the rapid fall of the Modern Data Stack is that it still requires an expert in the loop to run it efficiently. As Joe Reis mentioned in his Everything Ends - My Journey With the Modern Data Stack
The Next-Gen Data Stack will embrace this principle and build a feedback loop with all batteries included to enforce best practices in building data engineering practices. ConclusionThe journey of the modern data stack is a fascinating tale of innovation, growth, and eventual re-evaluation. From its mysterious origins and meteoric rise, marked by the democratization of data processing and scalability, to its downfall, driven by high costs and integration challenges, the modern data stack has profoundly shaped the landscape of data engineering. As we stand at the crossroads of this evolution, the lessons learned from the modern data stack are invaluable. The emergence of the Next-Gen Data Stack promises to build on these lessons, striving for open interoperability, enhanced developer productivity, and cost efficiency. By embracing these principles, the Next-Gen Data Stack aims to offer a more sustainable and user-friendly approach to data engineering. The story of data infrastructure is far from over. As technology continues to advance and new challenges arise, the ability to adapt and innovate will remain crucial. The modern data stack has paved the way, and now the Next-Gen Data Stack is poised to lead us into the future, offering hope for a more integrated and efficient data ecosystem. In this ever-evolving field, one thing is certain: the drive to harness the power of data will continue to inspire innovation, pushing the boundaries of what we can achieve. As we look ahead, the evolution of the data stack stands as a testament to the relentless pursuit of progress in data engineering.
|