Data Engineering Weekly #180
07-15-2024
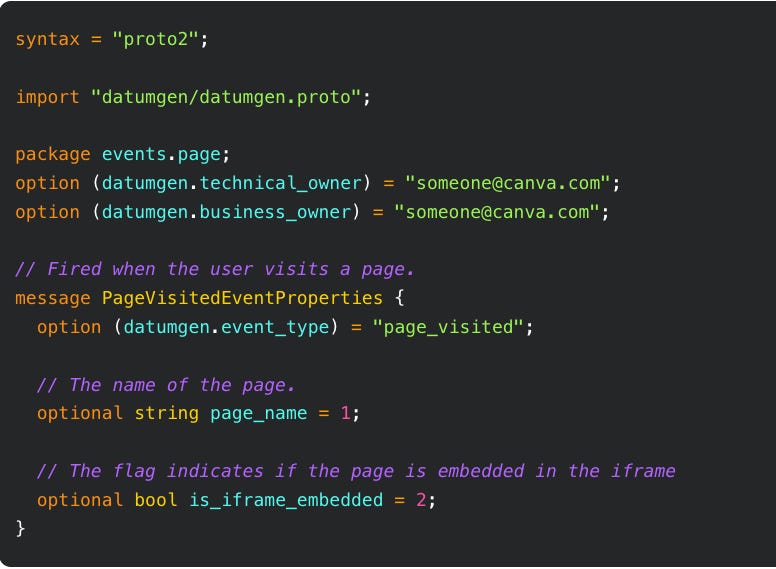
Canva: How Canva collects 25 billion events per dayCanva writes about its event collection infrastructure capabilities, handling 25 billion events per day (800 billion events per month) with 99.999% uptime.
The principle is the key motivation for me to write Schemata. If you want to adopt similar principles that Canva follows out of the box, you can use Schemata.
https://www.canva.dev/blog/engineering/product-analytics-event-collection/ Discord: How Discord Uses Open-Source Tools for Scalable Data Orchestration & TransformationDiscord writes about its migration journey from a homegrown orchestration engine to Dagster. The blog highlights the reasoning behind selecting dbt and Dagster and some of the key improvements while adopting them, such as handling race conditions in dbt incremental update and bulk backfilling with Dagster.
Philip Rathle: The GraphRAG Manifesto - Adding Knowledge to GenAIIt is one of the most fascinating reads about using Graphs as a structure to add knowledge to GenAI. The author highlights that there are two ways to represent knowledge.
The vector representation is an array of numbers. In a RAG context, it is useful when you want to identify how similar one handful of words is to another. The author is making a case where if you want to make sense of what’s inside of a vector, understand what’s around it, get a handle on the things represented in your text, or understand how any of these fit into a larger context, then vectors as a representation just aren’t able to do that. The graph is an appropriate model to represent knowledge. https://neo4j.com/blog/graphrag-manifesto/ Sponsored: 7/25 Amazon Bedrock Data Integration Tech Talk
Learn about:
Wasteman.codes: Engineering Principles for Building Financial SystemsAny system that involves moving money or counting money is always complex to get it correct. I used to joke the entire Walstreet runs on unknown SQL codes that no one understands. The author highlights the engineering best practices such as,
I’m a bit confused by the recommendation to use preferred integers to represent financial amounts since precision is critical in all financial computing. It would be helpful if the author added more context to the recommendation. https://substack.wasteman.codes/p/engineering-principles-and-best-practices Mark Raasveldt: Memory Management in DuckDBMemory management is one of the hardest parts of building in-memory database engines while supporting large-scale data processing. The author writes an in-depth overview of key parts of DuckDB memory optimization techniques.
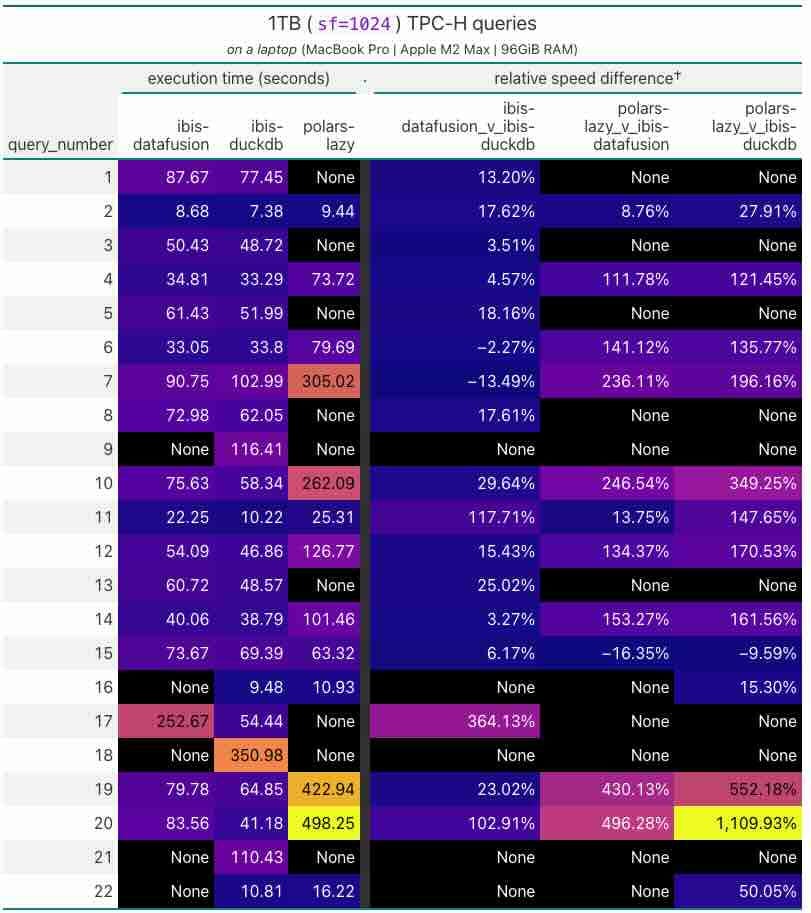
https://duckdb.org/2024/07/09/memory-management Ibis: Querying 1TB on a laptop with Python dataframesIbis is an open-source dataframe framework to interact with multiple database engines. Ibis published a 1TB benchmark processing MacBook Pro with 96 GiB of RAM comparing Ibis, Pandas & variations of Polaris.
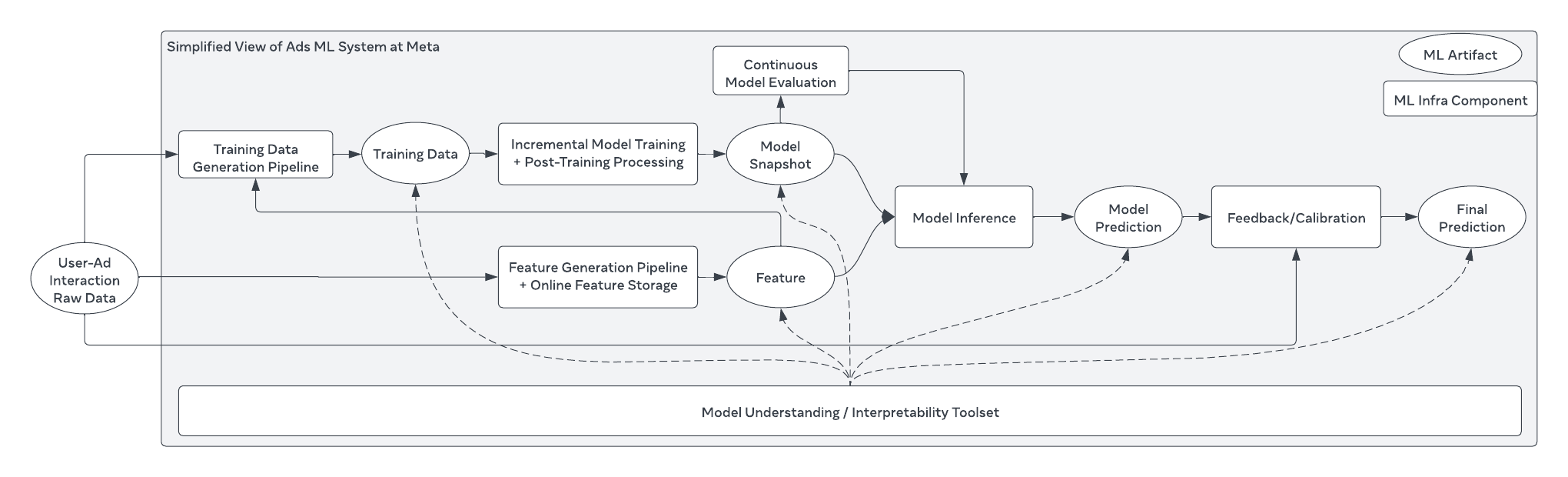
https://ibis-project.org/posts/1tbc/ Max Zheng: Contact & Organization EnrichmentFinding your champion product advocate within your user base is critical in enterprise selling. Metabase writes about why they build a continuous enrichment pipeline for customer contacts pipeline and its system design. The blog provided a nice comparison summary of various 3rd-party data providers in this space and their capabilities. https://metabase.notion.site/Contact-Organization-Enrichment-dc974a4092674d2dab4da1fc01e57458 Meta: Meta’s approach to machine learning prediction robustnessMeta writes about its approach to machine learning prediction robustness and the challenges of ensuring reliable ML predictions. The authors identify several factors that make this difficult, including the stochastic nature of ML models and the constant updates to models and features. Meta’s approach to addressing these challenges involves a systematic framework incorporating preventative measures, fundamental understanding, and technical fortifications.
Dropbox: Bringing AI-powered answers and summaries to file previews on the webDropbox writes about building AI-powered features such as Q&A and summaries on unstructured data. The blog highlights optimization techniques to build embedding to enable such features.
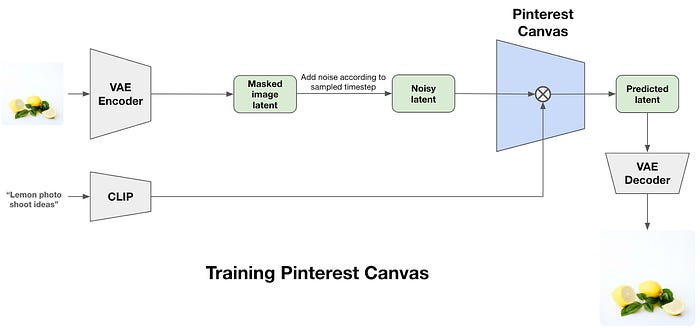
The lessons learned section highlights the key factors to consider while building, especially around clustering & segmentation, chunk priority calculation, and cached embeddings. Pinterest: Building Pinterest Canvas, a text-to-image foundation modelPinterest writes about Canvas, its homegrown text-to-image foundation model designed to generate images from textual descriptions.
The blog details the process of generating high-quality training datasets to build the base model and fine-tune the model further to create personalized experiences. All rights reserved ProtoGrowth Inc, India. I have provided links for informational purposes and do not suggest endorsement. All views expressed in this newsletter are my own and do not represent current, former, or future employer” opinions.
|