Data Engineering Weekly #177
06-24-2024
Experience Enterprise-Grade Apache AirflowAstro augments Airflow with enterprise-grade features to enhance productivity, meet scalability and availability demands across your data pipelines, and more. Redpoint: The InfraRed ReportThe impact of macroeconomic slowness results in increased focus on prioritizing reduced infrastructure spending. Redpoint’s InfraRed report shows a promising sign of a rebound in spending, where much of the money goes to GenAI. A few highlights from the report
https://www.redpoint.com/infrared/report/ Bessemer Venture Partners: Roadmap: AI InfrastructureCompanies are increasing their investment in AI but struggle to integrate it with their product experience or find the right talent and infrastructure to empower it. Bessemer publishes the Data + AI infrastructure market map to help companies understand the landscape and the key players.
https://www.bvp.com/atlas/roadmap-ai-infrastructure Shreya Shankar: Short Musings on AI Engineering and "Failed AI Projects"LLMs significantly reduce the entry barrier and are faster than ever for prototypes. The author highlights that while people ship initial deployments of LLM-based pipelines much faster than traditional ML pipelines, expectations become similarly tempered once they are in production. Should we term this as an AI product curve of disappointment?
https://www.sh-reya.com/blog/ai-engineering-short/ Sponsored: 2024 State of Apache Airflow ReportGain access to the latest trends and insights shaping the world of Apache Airflow—the go-to platform for data pipeline development and orchestration.
Sem Sinchenko: Unity Catalog - The First Look
A balanced take on the open source version of Unity Catalog, what is in the open source, and what is in the commercial version. While seeing the Unity Catalog code, I thought it might be a stripped-down version of the code used in production. But it seems a complete rewrite. It is still unclear if Databricks will use the open-source version in their prod. I guess it is okay to build something from scratch, but I was surprised it was announced on the stage as if Databricks open-source their production version of the Unity catalog. https://semyonsinchenko.github.io/ssinchenko/post/uniticatalog-first-look/ Netflix: A Recap of the Data Engineering Open Forum at NetflixNetflix publishes a recap of all the talks in the first Data Engineering open forum tech meetups. The blog contains a summary of each talk and a link to the YouTube channel with all the talks.
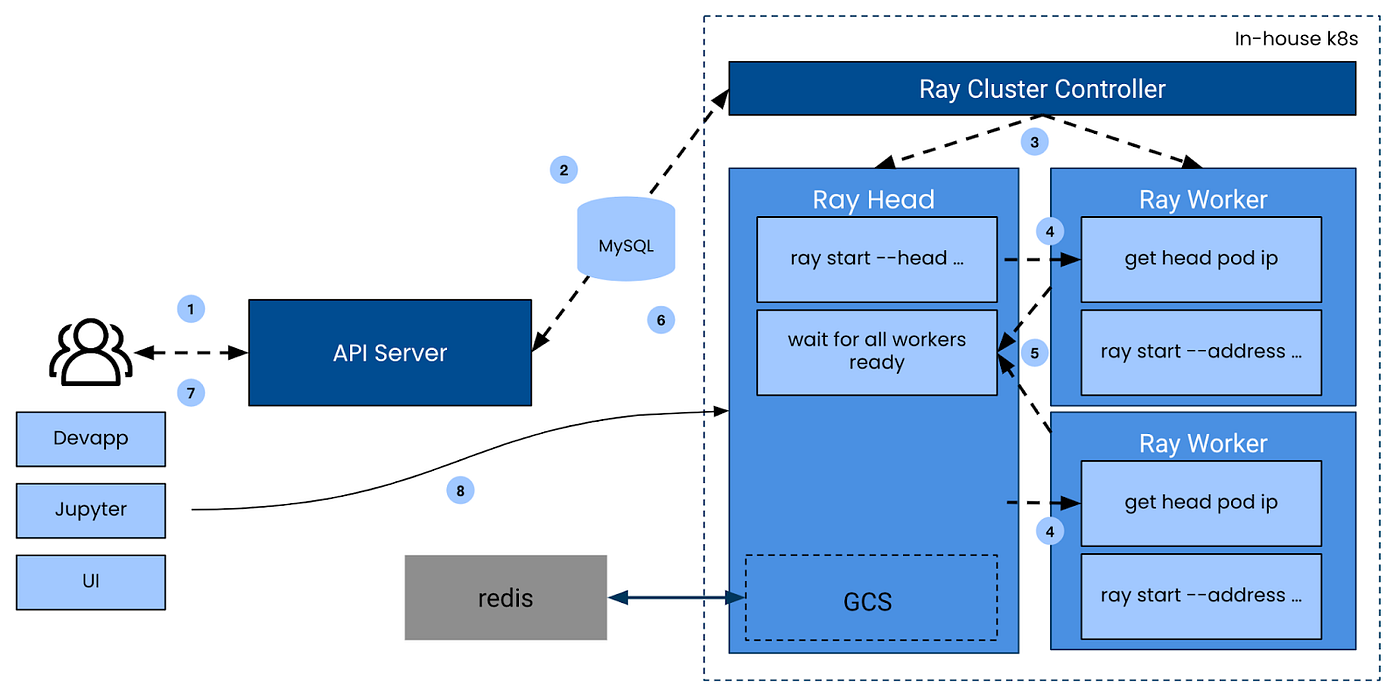
https://netflixtechblog.com/a-recap-of-the-data-engineering-open-forum-at-netflix-6b4d4410b88f Pinterest: Ray Infrastructure at PinterestPinterest writes about the challenges of running Ray infrastructure in production and integration with the existing Pinterest ecosystem. The case study is a classic success of the platform engineering with a wrapers around the cluster to ease the usage and increases the adaptability.
https://medium.com/pinterest-engineering/ray-infrastructure-at-pinterest-0248efe4fd52 Lyft: ETA (Estimated Time of Arrival) Reliability at LyftAnother platform engineering case study where Lyft writes about computing ETA to show the availability of the ride and its challenges in building real-time. The blog details the classification model, training approach and historical data analysis.
https://eng.lyft.com/eta-estimated-time-of-arrival-reliability-at-lyft-d4ca2720bda8 Allegro Tech: A Mission to Cost-Effectiveness: Reducing the cost of a single Google Cloud Dataflow Pipeline by Over 60%The blog is an excellent case study of hyopoesis driven cost optimization with the detail analysis to verify the hypothesis. The author highlighted three hypothesis contributing cost in Google Cloud Dataflow pipeline.
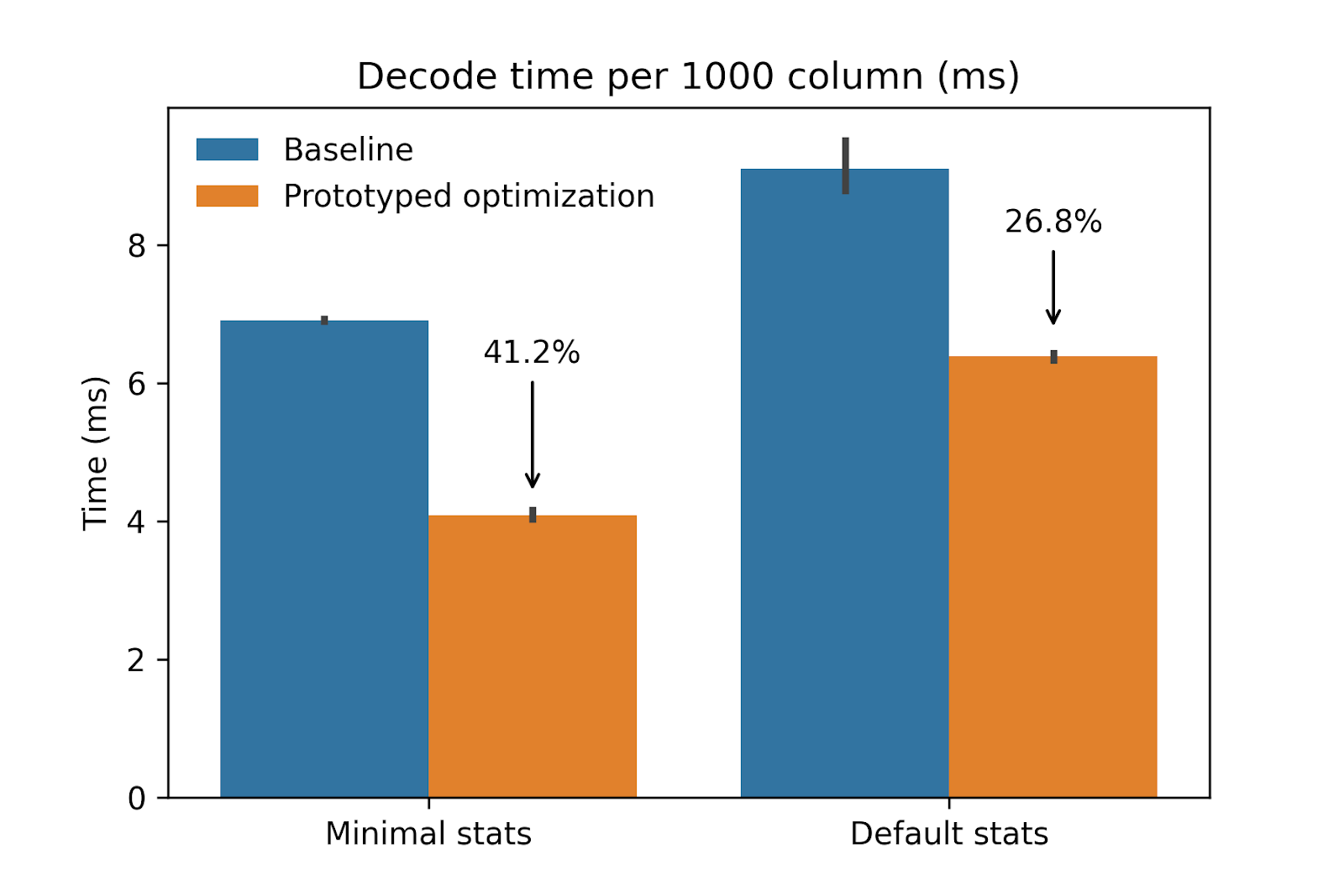
https://blog.allegro.tech/2024/06/cost-optimization-data-pipeline-gcp.html Apurva Mehta: Stream Processing is more ubiquitous than you thinkIt’s common to find in many data trends prediction that this year will be the year of stream processing, however Michael Drogalis highlighted there are not many usecases for stream processing. Ref: https://x.com/MichaelDrogalis/status/1782439448996970946 The author highlights the low latency, reactive usecases more ubiquitous than what we think? Question to the readers, what do you think of the current state of real-time data processing engines? Are there enough usecases? https://x.com/apurva1618/status/1803101801081975029?s=12&t=IJ8nTG5H26su2sWUh2bYSw Influx Data: How Good is Parquet for Wide Tables (Machine Learning Workloads) Really?Is parquet is still good enough for Machine Learning, Vector and Lake House workloads?
Influx data conclude that while technical concerns about Parquet metadata are valid, the actual overhead is smaller than generally recognized. In fact, optimizing writer settings and simple implementation tweaks can reduce overhead by 30-40%. With significant additional implementation optimization, decode speeds could improve by up to 4x. https://www.influxdata.com/blog/how-good-parquet-wide-tables/ All rights reserved ProtoGrowth Inc, India. I have provided links for informational purposes and do not suggest endorsement. All views expressed in this newsletter are my own and do not represent current, former, or future employer” opinions.
|