Data Science Weekly - Issue 553
06-27-2024
Data Science Weekly - Issue 553Curated news, articles and jobs related to Data Science, AI, & Machine Learning
Issue #553
|

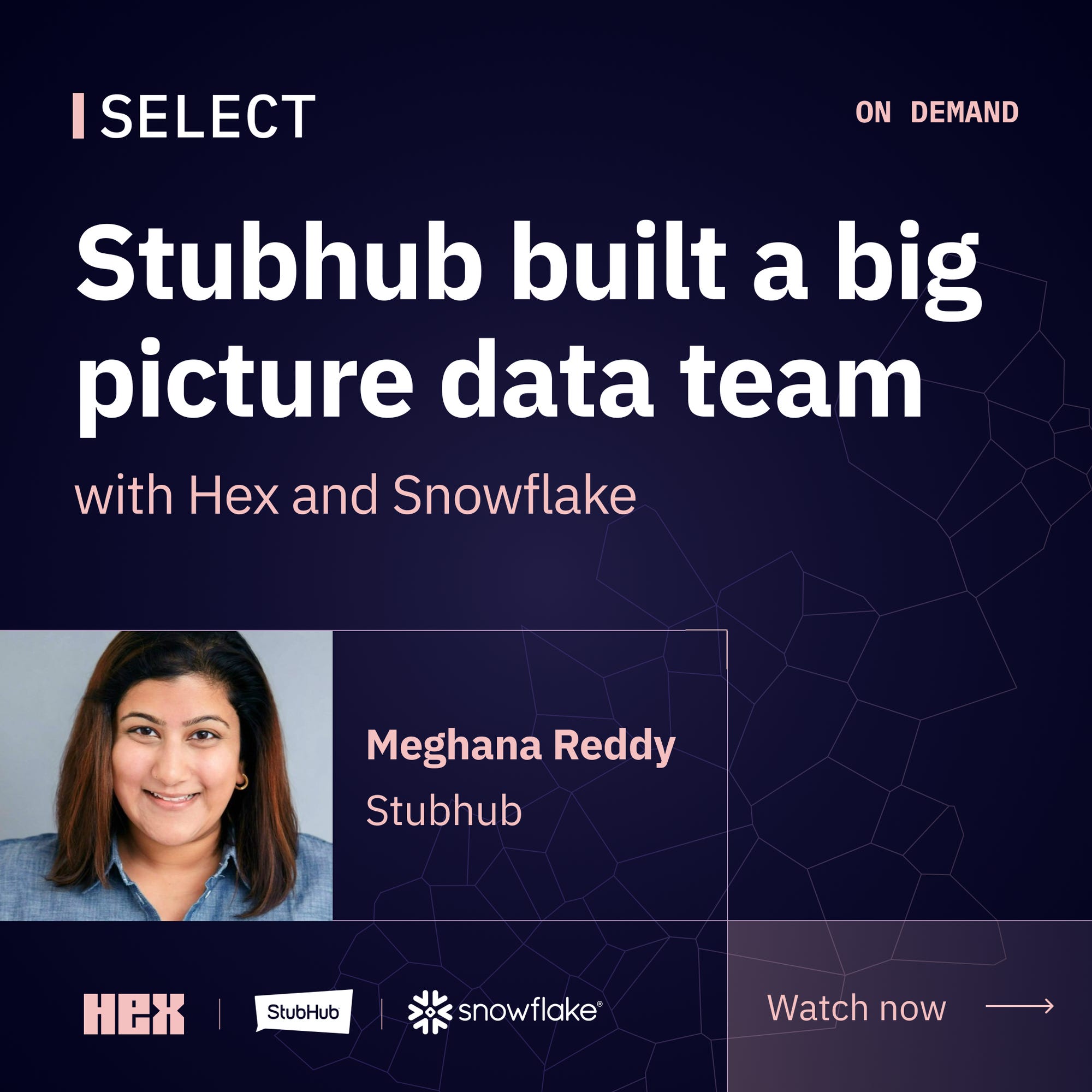 |
Building a Big Picture Data Team at StubHub
See how Meghana Reddy, Head of Data at StubHub, built a data team that delivers business insights accurately and quickly with the help of Snowflake and Hex.
The challenges she faced may sound familiar:
Unclear SMEs meant questions went to multiple people
Without SLAs, answer times were too long
Lack of data modeling & source-of-truth metrics generated varying results
Lack of discoverability & reproducibility cost time, efficiency and accuracy
Static reporting reserved interactivity for rare occasion
Register now to hear how Meghana and the StubHub data team tackled these challenges with Snowflake and Hex. And watch Meghana demo StubHub’s data apps that increase quality and speed to insights…
* Want to sponsor the newsletter? Email us for details --> team@datascienceweekly.org
Data Science Articles & Videos
-
What Is Confounding?
Thinking back to my Introduction to Epidemiology class, confounding was one of the topics of central interest. However, it took the remainder of my PhD (and then some) to really get what confounding was. Confounding was introduced as exposure and outcome having common cause…In what follows, I motivate confounding with a fairly typical example involving how a binary exposure affects risk of a binary outcome. We’ll discuss the “Right Way” to estimate the effect of the exposure as well as “The Wrong Way”. We’ll find that the confounding of the relationship between exposure and outcome comes down to a single fact: the wrong weights are applied to the right estimates… What I've Learned After A Decade Of Data Engineering
After 10 years of Data Engineering work, I think it’s time to hang up the proverbial hat and ride off into the sunset, never to be seen again. I wish. Everything has changed in 10 years, yet nothing has changed in 10 years, how is that even possible? Sometimes I wonder if I’ve learned anything at all, maybe I’m just like the moras of Data Warehouses moldering out there in forgotten and beaten SQL Servers. The technology has shifted drastically under my feet, yet I’ve managed to keep my fingernails firmly sunk into the edge of the cliff of technical and personal obsolesce that seems intent on dragging me away to the purgatory of useless programmers and tools…Last week’s summer school on probabilistic AI
Last week, the Nordic Summer School on Probabilistic AI took place in Copenhagen. I was fortunate to attend some of it (3 out of 5 days), and teach half a day on Monte Carlo methods. All the course material is available online. This includes slides, and extensive code demo and exercises. I believe recordings of the lectures will be released…I’d like to share some thoughts/ideas that came up in class and in the hallway, particularly on the topics of variational inference (VI) and Markov chain Monte Carlo (MCMC). This by no means covers all the subjects taught during the summer school; these are simply two topics close to home for me…What AI Engineers Should Know about Search
At least 50 of them :). I probably don’t need to discuss bi/cross-encoders, etc. A lot of great content is out there on those topics, especially folks like Pinecone, targeting the AI / LLM / RAG crowd. But maybe you to quickly get some high-level, historical, lexical search context… Well I’m here for ya! You might be new to all this. Hired into an “AI Engineer” role and suddenly needing to index a lot of search content :). Welcome to this brave world, there’s a lot you can contribute! Some things to know..Forking paths in LLMs for data analysis
I spent last week at a workshop where we were asked to prepare a short provocation related to interactive data analysis…In thinking about what could be said about the future of data analysis on the way there, I decided one can’t really consider the future of data analysis, including how to address issues of forking paths and replicability, without considering LLMs…This seemed like the right direction given that they asked for a provocation. After all, what better way to put people on edge these days than the cliche and annoying move of changing the topic of what is meant to be a serious academic conversation to focus on LLMs?…Automate code refactoring with {xmlparsedata} and {brio}
These are notes from a quite particular use case: what if you want to replace the usage of a function with another one in many scripts, without manual edits and without touching lines that do not contain a call to replace?…The real life example that inspired this post is the replacement of all calls toexpect_that(..., equals(...)), likeexpect_that(a, equals(1)), in igraph tests withexpect_equal(). If you’re a newer package developer who grew up with testthat’s third edition, you’ve probably never heard of that cutesy old-school testing style. 😉…Learning about AI in the data science classroom (My plans for Fall 2024)
If you, like me, always feel behind in everything especially when it comes to catching on the newest trends in education, you might also possibly been stressed about catching up on AI in the classroom. To change that I dedicated my Spring quarter catching up on learning about AI in the classroom. I tried to attend every event at the intersection of statistics + AI + education that fit my schedule and tried to read as much as possible. I am not an expert on the use of generative AI but as a learner, I want to share a few resources that I found helpful. In addition I will share my plans for my classes…Coding For Structured Generation with LLMs
In this post we're going to go through an example that shows not only how to use structured generation in your LLM code, but also gives an overview of the development process when working with structured generation. If you've been working with LLMs a lot, and focusing primarily on prompting, I think you'll be surprised how much writing structured generation code with LLMs feels like real engineering again…-
The Simons Institute for the Theory of Computing YouTube Page
The Simons Institute brings together the world's top researchers in theoretical computer science and related fields, as well as the next generation of outstanding young scholars, to explore deep unsolved problems about the nature and limits of computation…
How to think about creating a dataset for LLM finetuning evaluation
I summarize the kinds of evaluations that are needed for a structured data generation task…I'm in the process of coding up the manual evaluation data set for my LLM finetuning work around structured data. I wrote this blog to capture the high-level categories for how I'm thinking about these kinds of 'unit-test'-like evaluations of LLM output…Announcing the Build with Claude June 2024 contest
Announcing the Build with Claude June 2024 contest. We're giving out $30k in Anthropic API credits. All you need to do is build and share an app that uses Claude through the Anthropic API…Boosting vs. semi-supervised learning
While gradient boosted algorithms are amazing, they aren't a silver bullet for everything. Especially when you're dealing with a dataset that only has a very small set of labels. For those use-cases you may want to resort to semi-supervised learning techniques instead…
Training & Resources
TinyML and Efficient Deep Learning Computing
This course focuses on efficient machine learning and systems. This is a crucial area as deep neural networks demand extraordinary levels of computation, hindering its deployment on everyday devices and burdening the cloud infrastructure. This course introduces efficient AI computing techniques that enable powerful deep learning applications on resource-constrained devices. Topics include model compression, pruning, quantization, neural architecture search, distributed training, data/model parallelism, gradient compression, and on-device fine-tuning. It also introduces application-specific acceleration techniques for large language models and diffusion models. Students will get hands-on experience implementing model compression techniques and deploying large language models (Llama2-7B) on a laptop…History of Graph Databases - Part 1
With this first of two videos, Prof. Semih Salihoglu discusses the history of database systems based on graph-based data models. This is a fascinating history that includes many systems, from the very first database system in history called IDS, which was based on a model called the "network model" and to the modern property graph databases, such as Neo4j and Kùzu, from document stores, such as MongoDB to RDF systems…A New Package for Making Charts in Emacs: eplot
So why didn’t I just use this PHP thing for my charts? Well, while it’s really convenient to generate stuff on a web server — that’s not really very convenient when you’re futzing around in Emacs with some numbers. There’s a reason Excel and Jupyter Notebooks are so popular, after all — interactively massaging the data until it shows what you want it to show is where it’s at. I mean, giving others an optimal experience of the data…
Last Week's Newsletter's 3 Most Clicked Links
* Based on unique clicks.
** Find last week's issue #552 here.
Cutting Room Floor
Structured prior distributions for the covariance matrix in latent factor models
MLX-vs-PyTorch: Benchmarks comparing PyTorch and MLX on Apple Silicon GPUs
-
Detecting hallucinations in large language models using semantic entropy
Whenever you're ready, 2 ways we can help:
Looking to get a job? Check out our “Get A Data Science Job” Course
It is a comprehensive course that teaches you everything related to getting a data science job based on answers to thousands of emails from readers like you. The course has 3 sections: Section 1 covers how to get started, Section 2 covers how to assemble a portfolio to showcase your experience (even if you don’t have any), and Section 3 covers how to write your resume.Promote yourself/organization to ~62,000 subscribers by sponsoring this newsletter. 35-45% weekly open rate.
Thank you for joining us this week! :)
Stay Data Science-y!
All our best,
Hannah & Sebastian
Invite your friends and earn rewards
![]()
![]()