Newsletters From:
The Analytics Engineering Roundup | Tristan Handy | Substack
The internet's most useful articles on analytics engineering and its adjacent ecosystem. Curated with ❤️ by Tristan Handy. Click to read The Analytics Engineering Roundup, a Substack publication with tens of thousands of subscribers.

Data work from the Goldilocks Zone and Medium Code
06-30-2024
Hi folks! Back on the roundup here to talk through the goings on from across the data ecosystem. Fresh dbt best practices: We recently published major updates to our dbt Mesh and dbt Semantic Layer best practices guides. These guides are written in conversation with the dbt Community as a collaborative way of synthesizing what we’ve all learned about the craft of analytics engineering. If one thing has been clear over the past few months it’s that the data space is evolving rapidly and will continue to do so - we’re committed to providing the tools and the resources that data practitioners need to keep up with the changing landscape.
The Goldilocks Zone and the Rise of Medium CodeThis past week I read two articles that are each fascinating independently, but taken together paint a compelling picture of the future of data work.
Let’s start with Medium Code. Readers of this newsletter are likely intimately familiar with one category of profession that blends domain expertise and software engineering best practices - analytics engineering. Analytics engineering was based on the idea that data analysis and other data work, traditionally locked up either in spreadsheets or slow moving enterprise ETL workflows. The rise of cloud data warehouses made it much easier to run more analytics workloads, more frequently, with less technical overhead. Far from leading to the downfall of data as a profession, it enabled the creation of analytics engineering and allowed for data professionals to be able to provide more output than before. Nick applies a level of abstraction to this with the generalizable concept of a “Medium Code” practitioner. Medium code practitioners can essentially be thought of as an emerging class of practitioners that blend traditional domain experts with code-based technical professions. Critically, they can provide much of the value of software engineering workflows, without having to be software engineers themself.
So what exactly does a medium-code practitioner do / not do?
It’s very useful to have the abstraction of Medium Code, not only does it clarify the work of analytics engineering but it frames it as part of a broader pattern emerging. Nick brings up the fact in data we have analytics engineers (analysts x software engineer) and data scientist (statistician x software engineer), but that we can also consider users everything from Infrastructure as code tools like Terraform to next.js developers as medium code practitioners. You can imagine similar patterns taking place across the org chart. Medium Code and LLMsThe blending of domain expertise and technical systems makes people that work in medium code a natural fit for owning and adopting LLM based workflows. One funny thing about writing these days is you’re also implicitly making a bet on how AI will progress. Nick thinks we’re going to end up in the Goldilocks Zone where LLM systems will meaningfully increase the productivity and impact of knowledge workers, but will not be taking the driver’s seat for the most complex or important work we do.
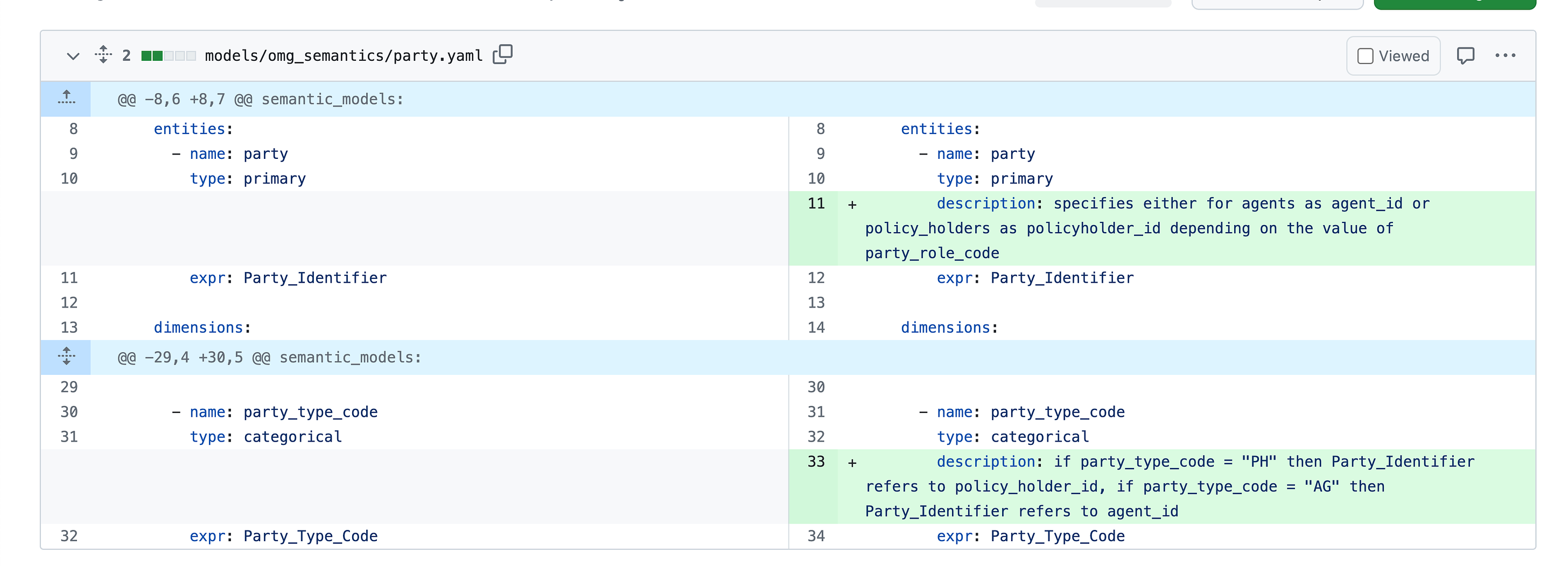
This suggests a world where all of the expertise we have been building not only stays relevant, but becomes even more relevant as AI tooling scales the impact of technical domain experts. We solve a hard problem once, encode it in a Medium Code system and then the LLMs are able to integrate that knowledge. My first taste of working in the Goldilocks Zone We can think of this as data work in the Goldilocks Zone¹, where LLMs provide a powerful new toolset that removes a huge amount of toil and extends the benefit of the work that we do. I felt this hands on last fall, when myself and the DX team were working to recreate a natural language → data benchmark in the dbt Semantic Layer. A paper had just come out showing that tools like knowledge graphs can make LLMs more reliable when working with data questions. We had gotten the skeleton of the project working, with our metrics built, our connection to the LLM built out and our prompt down. But we were stubbornly not getting the right answers to a few of the questions. The reason - this was a pretty thorny dataset. This bunch of questions all required you to filter on a specific column to determine whether a specific ID was referring to "policyholders" or "agents." So I went in and I added a simple change to the project. I described my understanding of the data, in natural language, in the description of the fields and dimensions that were relevant to this query.
All of a sudden - every question that had been failing due to this confusing naming scheme went from returning the correct answer 0% of the time to returning the correct answer nearly 100% of the time.
I had this really visceral sense that I had, for the very first time, performed a workflow that moving forward would fundamentally change how I work. I’ve felt this way exactly once before in my career, when I first got introduced to dbt in 2017. Much like cloud data warehouses extended the impact of data work and gave rise to the data flavored medium code workflows we know and love, in the Goldilocks Zone LLMs will extend this impact once further. You’ll still need to know understand your data, craft well architected data pipelines and understand the human and technical systems downstream from them. But the impact of your work will be magnified by a new set of tools that allows you to encode more of your baseline knowledge into these systems, letting you move up the stack and focus on higher order problems. This newsletter is sponsored by dbt Labs. Discover why more than 30,000 companies use dbt to accelerate their data development.
1
Adding my normal caveat here that this is one view of the progress AI could take - maybe progress stalls tomorrow and these systems never prove more than toys or maybe 3 years from now we’re all embroiled in The Project - this is just one view of what the future might hold
|


06-20-2024
Welcome to the Analytics Engineering Roundup
Thank you for subscribing to The Analytics Engineering Roundup ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏
Read More06-30-2024
Data work from the Goldilocks Zone and Medium Code
Not too hot, not too cold... just right ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏
Read More